
Fluentd vs Logstash
Nov 19, 2013 · 6 minute read · Commentslogging realtime fluentd logstash architecture
Fluentd and Logstash are two open-source projects that focus on the problem of centralized logging. Both projects address the collection and transport aspect of centralized logging using different approaches.
This post will walk through a sample deployment to see how each differs from the other. We’ll look at the dependencies, features, deployment architecture and potential issues. The point is not to figure out which one is the best, but rather to see which one would be a better fit for your environment.
The example setup we’ll walk through is collecting web server logs on multiple hosts and archiving them to S3:
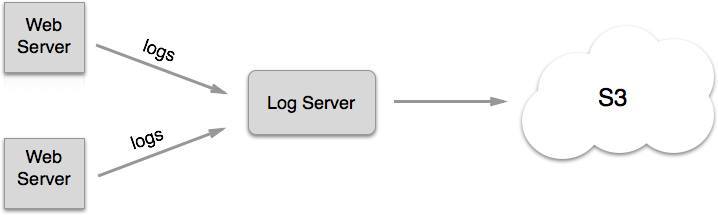
This type of architecture would be suitable for archival or processing with Hive or Pig.
Another common architecture is storing logs in ElasticSearch to make them searchable with Kibana or Graylog2. Setting that up is somewhat independent of using Logstash or Fluentd so I’ve left that out to keep things simple.
Installation Requirements
Logstash
Logstash is a JRuby based application which requires the JVM to run. Since it runs on the JVM, it can run anywhere the JVM does, which is usually means Linux, Mac OSX, and Windows. The package is shipped as single executable jar file which makes it very easy to install.
One of the downsides of depending on the JVM is that it’s memory footprint can be higher than you would want for transporting logs. Fortunately, Lumberjack can be run on individual hosts to collect and ship logs and Logstash can be run on the centralized log hosts.
Lumberjack is a Go based project with a much smaller memory
and CPU footprint. Deployment is still straightforward as Logstash and is basically installing a single
binary. The project provides deb and rpm packages to make it easier to deploy.
An SSL certificates is required to setup authentication between Lumberjack and Logstash which is
a little more complicated, but a nice benefit that encrypted transport is the default.
Fluentd
Fluentd is a CRuby application which requires Ruby 1.9.2 or later. There is an open-source version, fluentd, as well as a commercial version, td-agent. Fluentd runs on Linux and Mac OSX, but does not run on Windows currently.
For larger installs, they recommend using jemalloc to
avoid memory fragmentation. This is included in the deb and rpm packages but needs to be installed
manually if using the open-source version.
If you use the open-source version, you’ll need to install Fluentd from source or via gem install.
Since Fluentd is primarily developed by a commercial company, their deb and rpm packages are
configured to send data to their hosted centralized logging platform.
Apart from Ruby, they also recommend running ntpd which you should be running anyways.
Feature Comparison
Logstash supports a number of inputs, codecs, filters and outputs. Inputs are sources of data. Codecs essentially convert an incoming format into an internal Logstash representation as well as convert back out to an output format. These are usually used if the incoming message is not just a single line of text. Filters are processing actions on events and allow you to modify events or drop events as they are processed. Finally, outputs are destinations where events can be routed.
Fluentd is similar in that it has inputs and outputs and a matching mechanism to route log data between destinations. Internally, log messages are converted to JSON which provides structure to an unstructered log message. Messages can be tagged and then routed to different outputs.
Both projects have very similar capabilities and highlighting the difference between them from a feature standpoint is difficult. They both have plugin models that allow you to extend their functionality if needed. They also have rich repository of plugins already available.
Probably the most significant difference between Fluentd and Logstash is their design focus. Logstash emphasizes flexibility and interoperability whereas Fluentd prioritizes simplicity and robustness. This does not mean that Logstash is not robust or Fluentd is not flexible, rather each has prioritized features differently.
Fluentd has fewer inputs than Logstash, out of the box, but many of the inputs and outputs have built-in support for buffering, load-balancing, timeouts and retries. These types of features are necessary for ensuring data is reliably delivered.
For example, the out_forward plugin used to transfer logs from one fluentd instance to another has many robustness options that can be configured to ensure messages are delivered reliably.
Architecture comparison
From a deployment architecture standpoint, both frameworks are very similar. With Logstash, each web server would be configured to run Lumberjack and tail the web server logs. Lumberjack would forward the logs to a server running Logstash with a Lumberjack input. The Logstash server would also have an output configured using the S3 output. Since Lumberjack requires SSL certs, the log transfers would be encrypted from the web server to the log server.
With fluentd, each web server would run fluentd and tail the web server logs and forward them to another server running fluentd as well. This server would be configured to receive logs and write them to S3 using the S3 plugin. Fluentd does not support encryption so logs would be transferred unencrypted.
Update: @repeatedly pointed me to the fluent-plugin-secure-forward that some companies are using for encrypted transport.
Improving Availability
One central log server is a single point of failure. What happens if we wanted to have more than one central log server?
Lumberjack can be configured to use multiple servers but will only send logs to one until that one fails. If that happens, previously collected log data won’t be accessible until that host is resurrected. Essentially, it supports a master with hot-standby servers.
Fluentd on the other hand can forward two copies of the logs to each server if needed, load-balance between multiple hosts or have a master with a hot-standy in case of failure. There are lot of options for not only improving availabilty but also scalability if your log volume increases substantially. Keep in mind, that if you forward multiple copies, this could create duplicate logs in S3 which might need to be handled when you analyze them.
Potential Issues
The Logstash docs suggests using Redis as the receiving output if you run Logstash (not Lumberjack) on each host. This setup is based on Redis Lists and/or Pub/Sub which can lose messages if the receiver dies after removing the message from Redis and before it has had a chance to forward it along. Additionally, Redis would need to be configured with AOF to minimize the chance of lost messages if Redis were to fail.
There is a document describing the life of an event that discusses some of the failure modes and how Logstash addresses them. One important point is that outputs are responsible for retrying events in the case of errors. There are also internal, ephemeral queues within Logstash that can hold up to 20 events. Depending on the failure, there is a window for messages to be lost.
If you absolutely cannot risk losing messages, make sure you investigate all the failure modes and whether the plugins you are using are implemented correctly to handle them.
Update: LOGSTASH-1631 is a bug that demonstrates one way messages can be lost. It appears the internal messaging is going to be replaced with a more reliable implementation in the future.
Conclusion
Both Logstash and Fluentd are viable centralized logging frameworks that can transfer logs from multiple hosts to a central location. Logstash is incredibly flexible with many input and output plugins whereas fluentd provides fewer input and output sources but provides multiple options for reliably and robust transport.